|
|
---
|
|
|
|
|
|
Alias: [""]
|
|
|
Tag: [""]
|
|
|
Date: 2022-02-06
|
|
|
DocType: WebClipping
|
|
|
Hierarchy:
|
|
|
TimeStamp:
|
|
|
Link: https://github.com/stefanprodan/dockprom
|
|
|
location:
|
|
|
CollapseMetaTable: true
|
|
|
|
|
|
---
|
|
|
|
|
|
Parent:: [[Selfhosting|Self hosting]]
|
|
|
|
|
|
---
|
|
|
|
|
|
 
|
|
|
|
|
|
```button
|
|
|
name Save
|
|
|
type command
|
|
|
action Save current file
|
|
|
id Save
|
|
|
```
|
|
|
^button-PrometheusGrafanacAdvisorNodeExporterAlertManagerNSave
|
|
|
|
|
|
 
|
|
|
|
|
|
# GitHub - stefanprodan/dockprom: Docker hosts and containers monitoring with Prometheus, Grafana, cAdvisor, NodeExporter and AlertManager
|
|
|
|
|
|
|
|
|
|
|
|
A monitoring solution for Docker hosts and containers with [Prometheus](https://prometheus.io/), [Grafana](http://grafana.org/), [cAdvisor](https://github.com/google/cadvisor), [NodeExporter](https://github.com/prometheus/node_exporter) and alerting with [AlertManager](https://github.com/prometheus/alertmanager).
|
|
|
|
|
|
_**If you're looking for the Docker Swarm version please go to [stefanprodan/swarmprom](https://github.com/stefanprodan/swarmprom)**_
|
|
|
|
|
|
Install
|
|
|
-------
|
|
|
|
|
|
Clone this repository on your Docker host, cd into dockprom directory and run compose up:
|
|
|
|
|
|
git clone https://github.com/stefanprodan/dockprom
|
|
|
cd dockprom
|
|
|
|
|
|
ADMIN\_USER=admin ADMIN\_PASSWORD=admin ADMIN\_PASSWORD\_HASH=JDJhJDE0JE91S1FrN0Z0VEsyWmhrQVpON1VzdHVLSDkyWHdsN0xNbEZYdnNIZm1pb2d1blg4Y09mL0ZP docker-compose up -d
|
|
|
|
|
|
**Caddy v2 does not accept plaintext passwords. It MUST be provided as a hash value. The above password hash corresponds to ADMIN\_PASSWORD 'admin'. To know how to generate hash password, refer [Updating Caddy to v2](https://github.com/#Updating-Caddy-to-v2)**
|
|
|
|
|
|
Prerequisites:
|
|
|
|
|
|
* Docker Engine >= 1.13
|
|
|
* Docker Compose >= 1.11
|
|
|
|
|
|
Updating Caddy to v2
|
|
|
--------------------
|
|
|
|
|
|
Perform a `docker run --rm caddy caddy hash-password --plaintext 'ADMIN_PASSWORD'` in order to generate a hash for your new password. ENSURE that you replace `ADMIN_PASSWORD` with new plain text password and `ADMIN_PASSWORD_HASH` with the hashed password references in [docker-compose.yml](https://github.com/stefanprodan/dockprom/blob/master/docker-compose.yml) for the caddy container.
|
|
|
|
|
|
Containers:
|
|
|
|
|
|
* Prometheus (metrics database) `http://<host-ip>:9090`
|
|
|
* Prometheus-Pushgateway (push acceptor for ephemeral and batch jobs) `http://<host-ip>:9091`
|
|
|
* AlertManager (alerts management) `http://<host-ip>:9093`
|
|
|
* Grafana (visualize metrics) `http://<host-ip>:3000`
|
|
|
* NodeExporter (host metrics collector)
|
|
|
* cAdvisor (containers metrics collector)
|
|
|
* Caddy (reverse proxy and basic auth provider for prometheus and alertmanager)
|
|
|
|
|
|
Setup Grafana
|
|
|
-------------
|
|
|
|
|
|
Navigate to `http://<host-ip>:3000` and login with user _**admin**_ password _**admin**_. You can change the credentials in the compose file or by supplying the `ADMIN_USER` and `ADMIN_PASSWORD` environment variables on compose up. The config file can be added directly in grafana part like this
|
|
|
|
|
|
grafana:
|
|
|
image: grafana/grafana:7.2.0
|
|
|
env\_file:
|
|
|
- config
|
|
|
|
|
|
and the config file format should have this content
|
|
|
|
|
|
GF\_SECURITY\_ADMIN\_USER=admin
|
|
|
GF\_SECURITY\_ADMIN\_PASSWORD=changeme
|
|
|
GF\_USERS\_ALLOW\_SIGN\_UP=false
|
|
|
|
|
|
If you want to change the password, you have to remove this entry, otherwise the change will not take effect
|
|
|
|
|
|
\- grafana\_data:/var/lib/grafana
|
|
|
|
|
|
Grafana is preconfigured with dashboards and Prometheus as the default data source:
|
|
|
|
|
|
* Name: Prometheus
|
|
|
* Type: Prometheus
|
|
|
* Url: [http://prometheus:9090](http://prometheus:9090/)
|
|
|
* Access: proxy
|
|
|
|
|
|
_**Docker Host Dashboard**_
|
|
|
|
|
|
[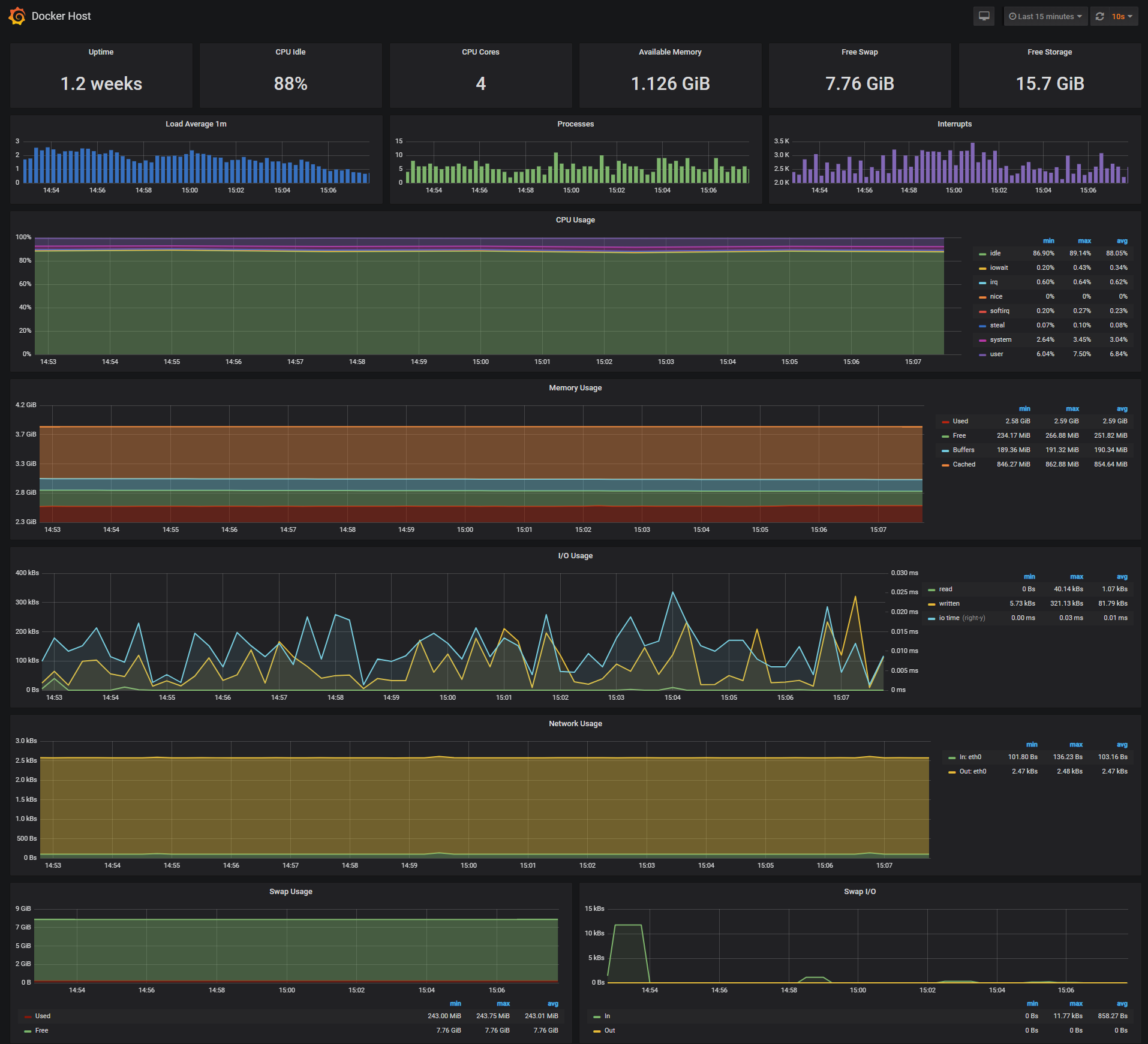](https://raw.githubusercontent.com/stefanprodan/dockprom/master/screens/Grafana_Docker_Host.png)
|
|
|
|
|
|
The Docker Host Dashboard shows key metrics for monitoring the resource usage of your server:
|
|
|
|
|
|
* Server uptime, CPU idle percent, number of CPU cores, available memory, swap and storage
|
|
|
* System load average graph, running and blocked by IO processes graph, interrupts graph
|
|
|
* CPU usage graph by mode (guest, idle, iowait, irq, nice, softirq, steal, system, user)
|
|
|
* Memory usage graph by distribution (used, free, buffers, cached)
|
|
|
* IO usage graph (read Bps, read Bps and IO time)
|
|
|
* Network usage graph by device (inbound Bps, Outbound Bps)
|
|
|
* Swap usage and activity graphs
|
|
|
|
|
|
For storage and particularly Free Storage graph, you have to specify the fstype in grafana graph request. You can find it in `grafana/provisioning/dashboards/docker_host.json`, at line 480 :
|
|
|
|
|
|
"expr": "sum(node\_filesystem\_free\_bytes{fstype=\\"btrfs\\"})",
|
|
|
|
|
|
I work on BTRFS, so i need to change `aufs` to `btrfs`.
|
|
|
|
|
|
You can find right value for your system in Prometheus `http://<host-ip>:9090` launching this request :
|
|
|
|
|
|
node\_filesystem\_free\_bytes
|
|
|
|
|
|
_**Docker Containers Dashboard**_
|
|
|
|
|
|
[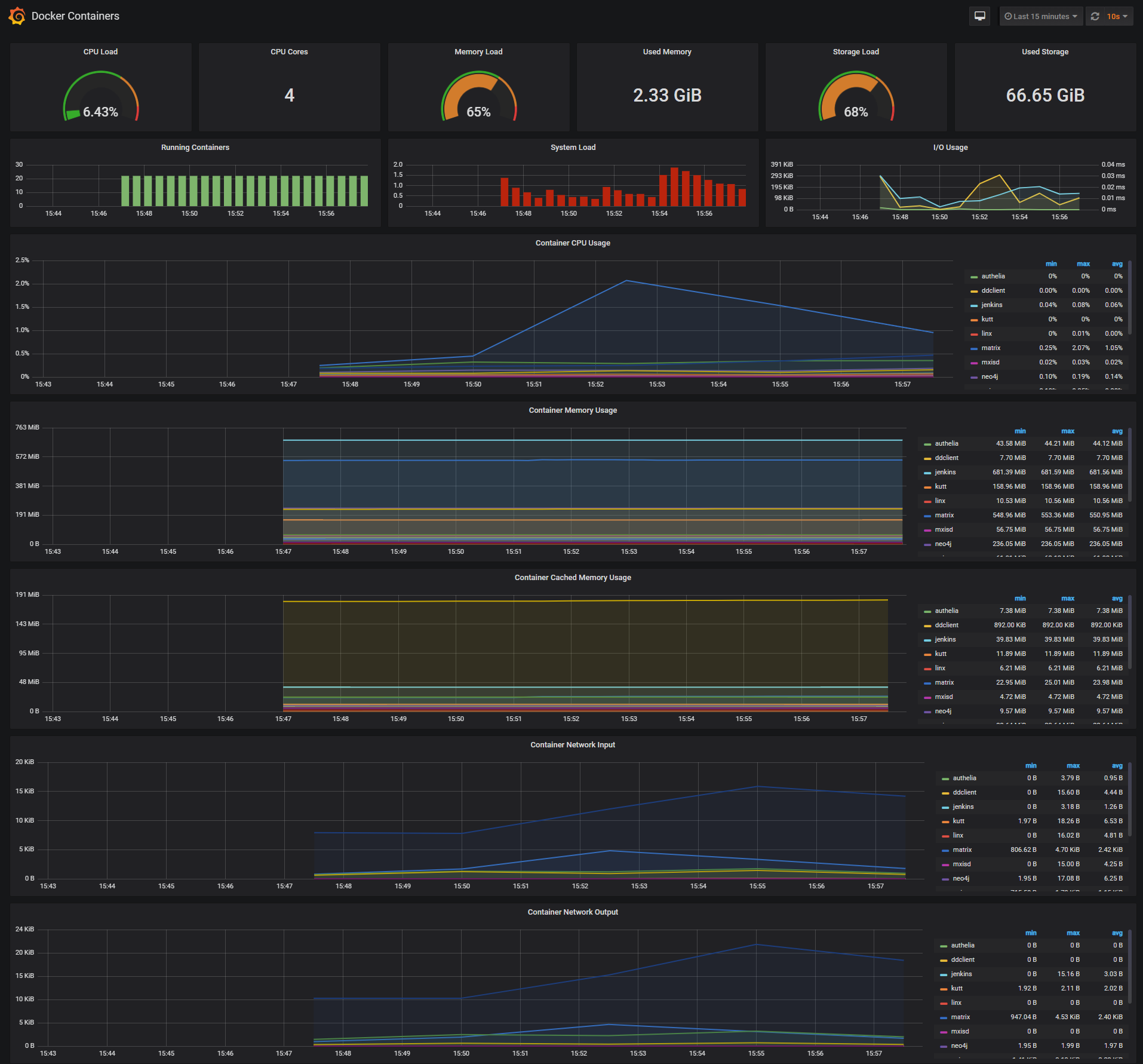](https://raw.githubusercontent.com/stefanprodan/dockprom/master/screens/Grafana_Docker_Containers.png)
|
|
|
|
|
|
The Docker Containers Dashboard shows key metrics for monitoring running containers:
|
|
|
|
|
|
* Total containers CPU load, memory and storage usage
|
|
|
* Running containers graph, system load graph, IO usage graph
|
|
|
* Container CPU usage graph
|
|
|
* Container memory usage graph
|
|
|
* Container cached memory usage graph
|
|
|
* Container network inbound usage graph
|
|
|
* Container network outbound usage graph
|
|
|
|
|
|
Note that this dashboard doesn't show the containers that are part of the monitoring stack.
|
|
|
|
|
|
_**Monitor Services Dashboard**_
|
|
|
|
|
|
[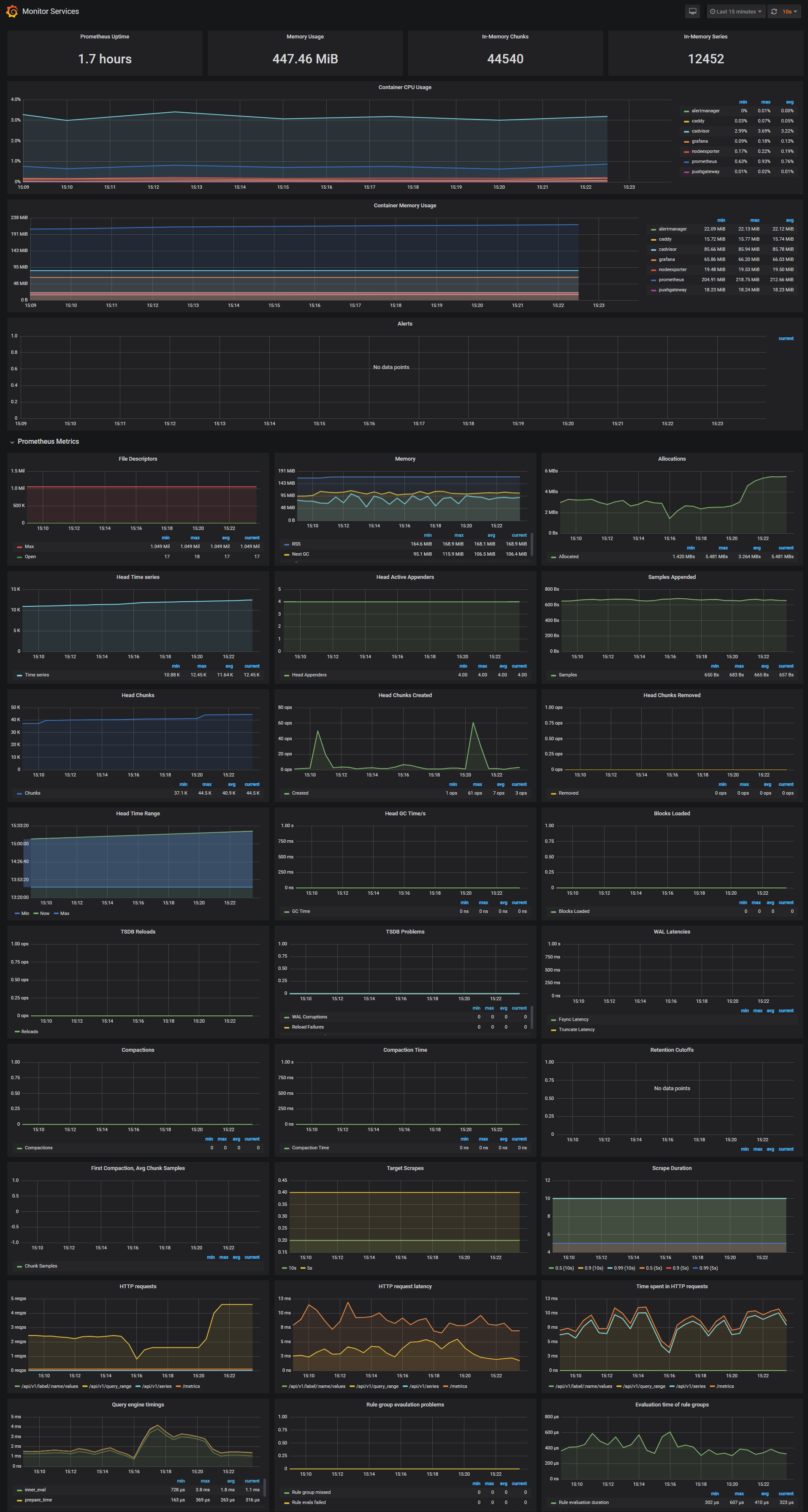](https://raw.githubusercontent.com/stefanprodan/dockprom/master/screens/Grafana_Prometheus.png)
|
|
|
|
|
|
The Monitor Services Dashboard shows key metrics for monitoring the containers that make up the monitoring stack:
|
|
|
|
|
|
* Prometheus container uptime, monitoring stack total memory usage, Prometheus local storage memory chunks and series
|
|
|
* Container CPU usage graph
|
|
|
* Container memory usage graph
|
|
|
* Prometheus chunks to persist and persistence urgency graphs
|
|
|
* Prometheus chunks ops and checkpoint duration graphs
|
|
|
* Prometheus samples ingested rate, target scrapes and scrape duration graphs
|
|
|
* Prometheus HTTP requests graph
|
|
|
* Prometheus alerts graph
|
|
|
|
|
|
Define alerts
|
|
|
-------------
|
|
|
|
|
|
Three alert groups have been setup within the [alert.rules](https://github.com/stefanprodan/dockprom/blob/master/prometheus/alert.rules) configuration file:
|
|
|
|
|
|
* Monitoring services alerts [targets](https://github.com/stefanprodan/dockprom/blob/master/prometheus/alert.rules#L2-L11)
|
|
|
* Docker Host alerts [host](https://github.com/stefanprodan/dockprom/blob/master/prometheus/alert.rules#L13-L40)
|
|
|
* Docker Containers alerts [containers](https://github.com/stefanprodan/dockprom/blob/master/prometheus/alert.rules#L42-L69)
|
|
|
|
|
|
You can modify the alert rules and reload them by making a HTTP POST call to Prometheus:
|
|
|
|
|
|
curl -X POST http://admin:admin@<host-ip\>:9090/-/reload
|
|
|
|
|
|
_**Monitoring services alerts**_
|
|
|
|
|
|
Trigger an alert if any of the monitoring targets (node-exporter and cAdvisor) are down for more than 30 seconds:
|
|
|
|
|
|
\- alert: monitor\_service\_down
|
|
|
expr: up == 0
|
|
|
for: 30s
|
|
|
labels:
|
|
|
severity: critical
|
|
|
annotations:
|
|
|
summary: "Monitor service non-operational"
|
|
|
description: "Service {{ $labels.instance }} is down."
|
|
|
|
|
|
_**Docker Host alerts**_
|
|
|
|
|
|
Trigger an alert if the Docker host CPU is under high load for more than 30 seconds:
|
|
|
|
|
|
\- alert: high\_cpu\_load
|
|
|
expr: node\_load1 > 1.5
|
|
|
for: 30s
|
|
|
labels:
|
|
|
severity: warning
|
|
|
annotations:
|
|
|
summary: "Server under high load"
|
|
|
description: "Docker host is under high load, the avg load 1m is at {{ $value}}. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
|
|
|
|
|
|
Modify the load threshold based on your CPU cores.
|
|
|
|
|
|
Trigger an alert if the Docker host memory is almost full:
|
|
|
|
|
|
\- alert: high\_memory\_load
|
|
|
expr: (sum(node\_memory\_MemTotal\_bytes) - sum(node\_memory\_MemFree\_bytes + node\_memory\_Buffers\_bytes + node\_memory\_Cached\_bytes) ) / sum(node\_memory\_MemTotal\_bytes) \* 100 > 85
|
|
|
for: 30s
|
|
|
labels:
|
|
|
severity: warning
|
|
|
annotations:
|
|
|
summary: "Server memory is almost full"
|
|
|
description: "Docker host memory usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
|
|
|
|
|
|
Trigger an alert if the Docker host storage is almost full:
|
|
|
|
|
|
\- alert: high\_storage\_load
|
|
|
expr: (node\_filesystem\_size\_bytes{fstype="aufs"} - node\_filesystem\_free\_bytes{fstype="aufs"}) / node\_filesystem\_size\_bytes{fstype="aufs"} \* 100 > 85
|
|
|
for: 30s
|
|
|
labels:
|
|
|
severity: warning
|
|
|
annotations:
|
|
|
summary: "Server storage is almost full"
|
|
|
description: "Docker host storage usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
|
|
|
|
|
|
_**Docker Containers alerts**_
|
|
|
|
|
|
Trigger an alert if a container is down for more than 30 seconds:
|
|
|
|
|
|
\- alert: jenkins\_down
|
|
|
expr: absent(container\_memory\_usage\_bytes{name="jenkins"})
|
|
|
for: 30s
|
|
|
labels:
|
|
|
severity: critical
|
|
|
annotations:
|
|
|
summary: "Jenkins down"
|
|
|
description: "Jenkins container is down for more than 30 seconds."
|
|
|
|
|
|
Trigger an alert if a container is using more than 10% of total CPU cores for more than 30 seconds:
|
|
|
|
|
|
\- alert: jenkins\_high\_cpu
|
|
|
expr: sum(rate(container\_cpu\_usage\_seconds\_total{name="jenkins"}\[1m\])) / count(node\_cpu\_seconds\_total{mode="system"}) \* 100 > 10
|
|
|
for: 30s
|
|
|
labels:
|
|
|
severity: warning
|
|
|
annotations:
|
|
|
summary: "Jenkins high CPU usage"
|
|
|
description: "Jenkins CPU usage is {{ humanize $value}}%."
|
|
|
|
|
|
Trigger an alert if a container is using more than 1.2GB of RAM for more than 30 seconds:
|
|
|
|
|
|
\- alert: jenkins\_high\_memory
|
|
|
expr: sum(container\_memory\_usage\_bytes{name="jenkins"}) > 1200000000
|
|
|
for: 30s
|
|
|
labels:
|
|
|
severity: warning
|
|
|
annotations:
|
|
|
summary: "Jenkins high memory usage"
|
|
|
description: "Jenkins memory consumption is at {{ humanize $value}}."
|
|
|
|
|
|
Setup alerting
|
|
|
--------------
|
|
|
|
|
|
The AlertManager service is responsible for handling alerts sent by Prometheus server. AlertManager can send notifications via email, Pushover, Slack, HipChat or any other system that exposes a webhook interface. A complete list of integrations can be found [here](https://prometheus.io/docs/alerting/configuration).
|
|
|
|
|
|
You can view and silence notifications by accessing `http://<host-ip>:9093`.
|
|
|
|
|
|
The notification receivers can be configured in [alertmanager/config.yml](https://github.com/stefanprodan/dockprom/blob/master/alertmanager/config.yml) file.
|
|
|
|
|
|
To receive alerts via Slack you need to make a custom integration by choose _**incoming web hooks**_ in your Slack team app page. You can find more details on setting up Slack integration [here](http://www.robustperception.io/using-slack-with-the-alertmanager/).
|
|
|
|
|
|
Copy the Slack Webhook URL into the _**api\_url**_ field and specify a Slack _**channel**_.
|
|
|
|
|
|
route:
|
|
|
receiver: 'slack'
|
|
|
|
|
|
receivers:
|
|
|
- name: 'slack'
|
|
|
slack\_configs:
|
|
|
- send\_resolved: true
|
|
|
text: "{{ .CommonAnnotations.description }}"
|
|
|
username: 'Prometheus'
|
|
|
channel: '#<channel>'
|
|
|
api\_url: 'https://hooks.slack.com/services/<webhook-id>'
|
|
|
|
|
|
[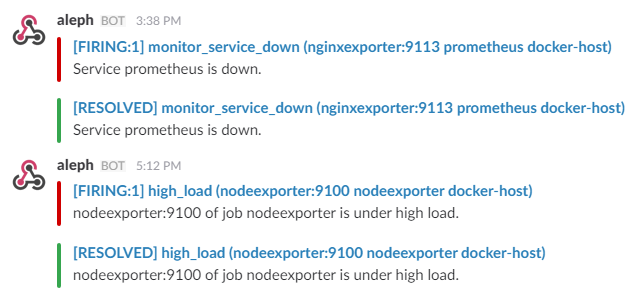](https://raw.githubusercontent.com/stefanprodan/dockprom/master/screens/Slack_Notifications.png)
|
|
|
|
|
|
Sending metrics to the Pushgateway
|
|
|
----------------------------------
|
|
|
|
|
|
The [pushgateway](https://github.com/prometheus/pushgateway) is used to collect data from batch jobs or from services.
|
|
|
|
|
|
To push data, simply execute:
|
|
|
|
|
|
echo "some\_metric 3.14" | curl --data-binary @- http://user:password@localhost:9091/metrics/job/some\_job
|
|
|
|
|
|
Please replace the `user:password` part with your user and password set in the initial configuration (default: `admin:admin`).
|
|
|
|
|
|
Updating Grafana to v5.2.2
|
|
|
--------------------------
|
|
|
|
|
|
[In Grafana versions >= 5.1 the id of the grafana user has been changed](http://docs.grafana.org/installation/docker/#migration-from-a-previous-version-of-the-docker-container-to-5-1-or-later). Unfortunately this means that files created prior to 5.1 won’t have the correct permissions for later versions.
|
|
|
|
|
|
| Version | User | User ID |
|
|
|
| --- | --- | --- |
|
|
|
| < 5.1 | grafana | 104 |
|
|
|
| \>= 5.1 | grafana | 472 |
|
|
|
|
|
|
There are two possible solutions to this problem.
|
|
|
|
|
|
1. Change ownership from 104 to 472
|
|
|
2. Start the upgraded container as user 104
|
|
|
|
|
|
Specifying a user in docker-compose.yml
|
|
|
---------------------------------------
|
|
|
|
|
|
To change ownership of the files run your grafana container as root and modify the permissions.
|
|
|
|
|
|
First perform a `docker-compose down` then modify your docker-compose.yml to include the `user: root` option:
|
|
|
|
|
|
grafana:
|
|
|
image: grafana/grafana:5.2.2
|
|
|
container\_name: grafana
|
|
|
volumes:
|
|
|
- grafana\_data:/var/lib/grafana
|
|
|
- ./grafana/datasources:/etc/grafana/datasources
|
|
|
- ./grafana/dashboards:/etc/grafana/dashboards
|
|
|
- ./grafana/setup.sh:/setup.sh
|
|
|
entrypoint: /setup.sh
|
|
|
user: root
|
|
|
environment:
|
|
|
- GF\_SECURITY\_ADMIN\_USER=${ADMIN\_USER:-admin}
|
|
|
- GF\_SECURITY\_ADMIN\_PASSWORD=${ADMIN\_PASSWORD:-admin}
|
|
|
- GF\_USERS\_ALLOW\_SIGN\_UP=false
|
|
|
restart: unless-stopped
|
|
|
expose:
|
|
|
- 3000
|
|
|
networks:
|
|
|
- monitor-net
|
|
|
labels:
|
|
|
org.label-schema.group: "monitoring"
|
|
|
|
|
|
Perform a `docker-compose up -d` and then issue the following commands:
|
|
|
|
|
|
docker exec -it --user root grafana bash
|
|
|
|
|
|
# in the container you just started:
|
|
|
chown -R root:root /etc/grafana && \\
|
|
|
chmod -R a+r /etc/grafana && \\
|
|
|
chown -R grafana:grafana /var/lib/grafana && \\
|
|
|
chown -R grafana:grafana /usr/share/grafana
|
|
|
|
|
|
To run the grafana container as `user: 104` change your `docker-compose.yml` like such:
|
|
|
|
|
|
grafana:
|
|
|
image: grafana/grafana:5.2.2
|
|
|
container\_name: grafana
|
|
|
volumes:
|
|
|
- grafana\_data:/var/lib/grafana
|
|
|
- ./grafana/datasources:/etc/grafana/datasources
|
|
|
- ./grafana/dashboards:/etc/grafana/dashboards
|
|
|
- ./grafana/setup.sh:/setup.sh
|
|
|
entrypoint: /setup.sh
|
|
|
user: "104"
|
|
|
environment:
|
|
|
- GF\_SECURITY\_ADMIN\_USER=${ADMIN\_USER:-admin}
|
|
|
- GF\_SECURITY\_ADMIN\_PASSWORD=${ADMIN\_PASSWORD:-admin}
|
|
|
- GF\_USERS\_ALLOW\_SIGN\_UP=false
|
|
|
restart: unless-stopped
|
|
|
expose:
|
|
|
- 3000
|
|
|
networks:
|
|
|
- monitor-net
|
|
|
labels:
|
|
|
org.label-schema.group: "monitoring" |